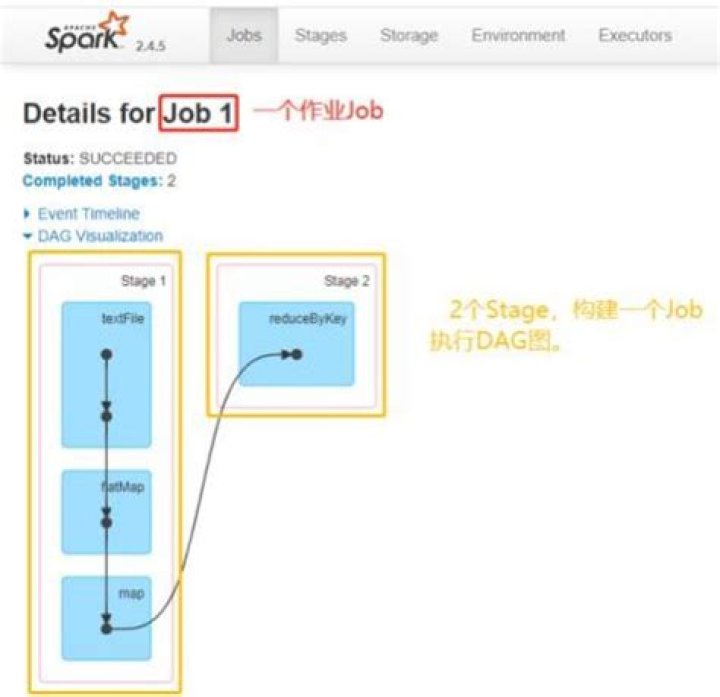
How do I install standalone Spark

Jessica Wood
Published Apr 28, 2026
Operating system: Ubuntu 14.04 or later, we can also use other Linux flavors like CentOS, Redhat, etc. … Download Scala. … Untar the file. … Edit Bashrc file. … Verifying Scala Installation. … Note: You can copy master-spark-Url from master web console ()
What is standalone mode in Spark?
Standalone mode is a simple cluster manager incorporated with Spark. It makes it easy to setup a cluster that Spark itself manages and can run on Linux, Windows, or Mac OSX. Often it is the simplest way to run Spark application in a clustered environment. Learn, how to install Apache Spark On Standalone Mode.
How do I install spark on Mac?
- Step 1: Install scala. brew install [email protected] Keep in mind you have to change the version if you want to install a different one.
- Step 2: Install Spark. brew install apache-spark.
- Step 3: Add environment variables. …
- Step 4: Review binaries permissions. …
- Step 5: Verify installation.
How do I install local machine on Spark?
- Step 1 – Download and install Java JDK 8. …
- Step 2 – Download and install Apache Spark latest version. …
- Step 3- Set the environment variables. …
- Step 4 – Update existing PATH variable. …
- Step 5 – Download and copy winutils.exe.
How do I put spark on my house?
- 3 Answers. You should install and set the SPARK_HOME variable, in unix terminal run the following code to set the variable: export SPARK_HOME=”/path/to/spark” …
- Specify SPARK_HOME and JAVA_HOME. As we have seen in the above function, for Windows we need to specifiy the locations. …
- Configure SparkContext.
Can spark work without Hadoop?
As per Spark documentation, Spark can run without Hadoop. You may run it as a Standalone mode without any resource manager. But if you want to run in multi-node setup, you need a resource manager like YARN or Mesos and a distributed file system like HDFS,S3 etc. Yes, spark can run without hadoop.
What is standalone and YARN mode?
In standalone mode you start workers and spark master and persistence layer can be any – HDFS, FileSystem, cassandra etc. In YARN mode you are asking YARN-Hadoop cluster to manage the resource allocation and book keeping.
How do I deploy a spark application?
- Step 1: Download Spark Ja. …
- Step 2: Compile program. …
- Step 3: Create a JAR. …
- Step 4: Submit spark application.
How do I get a spark master URL?
Just check where master is pointing to spark master machine. There you will be able to see spark master URI, and by default is spark://master:7077, actually quite a bit of information lives there, if you have a spark standalone cluster.
How do I run spark app?- Step 1: Verify if Java is installed. Java is a pre-requisite software for running Spark Applications. …
- Step 2 – Verify if Spark is installed. …
- Step 3: Download and Install Apache Spark:
How do I run spark locally in Intellij?
- Prepare an application to run. …
- Select Add Configuration in the list of run/debug configurations. …
- Click the Add New Configuration button ( ). …
- Fill in the configuration parameters: …
- Click OK to save the configuration. …
- Inspect the execution results in the Run tool window.
Do I need to install Scala for spark?
Learn more about Apache Spark from this Apache Spark Online Course and become an Apache Spark Specialist! If you don’t have Scala, then you have to install it on your system. … You need to download the latest version of Scala. Here, you will see the scala-2.11.
How do I know if Apache Spark is installed?
- Open Spark shell Terminal and enter command.
- sc.version Or spark-submit –version.
- The easiest way is to just launch “spark-shell” in command line. It will display the.
- current active version of Spark.
Can I use spark on my local machine?
Apache Spark is a fast and general-purpose cluster computing system. The first step is to download Spark from this link (in my case I put it in the home directory). … Then unzip the folder using command line, or right clicking on the *.
How do I run Scala on Mac?
- Step 1: Get Homebrew. …
- Step 2: Installing xcode-select. …
- Step 3: Use Homebrew to install Java. …
- Step 4: Use Homebrew to install Scala. …
- Step 5: Use Homebrew to install Apache Spark. …
- Step 5: Start the Spark Shell.
How do I get rid of spark on Mac?
- Open up Launchpad, and type Spark 2.1. 0.426 in the search box on the top.
- Click and hold Spark 2.1. 0.426 icon with your mouse button until it starts to wiggle. Then click the “X” that appears on the left upper corner of Spark 2.1. 0.426 to perform the uninstall.
How do I install Jupyter notebook on Mac?
- Step 1: Install the latest Python3 in MacOS.
- Step 2: Check if pip3 and python3 are correctly installed.
- Step 3: Upgrade your pip to avoid errors during installation.
- Step 4: Enter the following command to install Jupyter Notebook using pip3.
How do I download spark?
- Install Apache Spark on Windows. Step 1: Install Java 8. Step 2: Install Python. Step 3: Download Apache Spark. Step 4: Verify Spark Software File. Step 5: Install Apache Spark. Step 6: Add winutils.exe File. Step 7: Configure Environment Variables. Step 8: Launch Spark.
- Test Spark.
Where do I find spark config?
There is no option of viewing the spark configuration properties from command line. Instead you can check it in spark-default. conf file. Another option is to view from webUI.
How do I set environment variables in spark?
Spark Configuration Spark properties control most application parameters and can be set by using a SparkConf object, or through Java system properties. Environment variables can be used to set per-machine settings, such as the IP address, through the conf/spark-env.sh script on each node.
How do I start Apache spark?
- Download the latest. Get Spark version (for Hadoop 2.7) then extract it using a Zip tool that extracts TGZ files. …
- Set your environment variables. …
- Download Hadoop winutils (Windows) …
- Save WinUtils.exe (Windows) …
- Set up the Hadoop Scratch directory. …
- Set the Hadoop Hive directory permissions.
How can Spark be connected to Apache Mesos?
Connecting Spark to Mesos. To use Mesos from Spark, you need a Spark binary package available in a place accessible by Mesos, and a Spark driver program configured to connect to Mesos. Alternatively, you can also install Spark in the same location in all the Mesos agents, and configure spark.
How do I get Spark UI?
As long as the Spark application is up and running, you can access the web UI at .
Is Spark SQL faster than Hive?
Speed: – The operations in Hive are slower than Apache Spark in terms of memory and disk processing as Hive runs on top of Hadoop. Read/Write operations: – The number of read/write operations in Hive are greater than in Apache Spark. This is because Spark performs its intermediate operations in memory itself.
Which is better Spark or Hadoop?
Spark has been found to run 100 times faster in-memory, and 10 times faster on disk. It’s also been used to sort 100 TB of data 3 times faster than Hadoop MapReduce on one-tenth of the machines. Spark has particularly been found to be faster on machine learning applications, such as Naive Bayes and k-means.
Do we need HDFS for running Spark application?
Hadoop and Spark are not mutually exclusive and can work together. Real-time and faster data processing in Hadoop is not possible without Spark. On the other hand, Spark doesn’t have any file system for distributed storage. … Hence, HDFS is the main need for Hadoop to run Spark in distributed mode.
What are the different deployment modes of Apache spark?
- Local Mode (local[*],local,local[2]…etc) -> When you launch spark-shell without control/configuration argument, It will launch in local mode. …
- Spark Standalone cluster manger: -> spark-shell –master spark://hduser:7077. …
- Yarn mode (Client/Cluster mode): …
- Mesos mode:
How does Apache spark work?
Apache Spark is an open source, general-purpose distributed computing engine used for processing and analyzing a large amount of data. Just like Hadoop MapReduce, it also works with the system to distribute data across the cluster and process the data in parallel. … Each executor is a separate java process.
How do you set a spark master?
- Navigate to Spark Configuration Directory. Go to SPARK_HOME/conf/ directory. …
- Edit the file spark-env.sh – Set SPARK_MASTER_HOST. Note : If spark-env.sh is not present, spark-env.sh.template would be present. …
- Start spark as master. …
- Verify the log file.
How do I run a spark Scala program?
- Download the Scala binaries from the Scala Install page.
- Unpack the file, set the SCALA_HOME environment variable, and add it to your path, as shown in the Scala Install instructions. …
- Launch the Scala REPL. …
- Copy and paste HelloWorld code into Scala REPL. …
- Save HelloWorld.scala and exit the REPL.
How do I download spark from IntelliJ?
- Create Scala project. Once you have everything installed, first step is to create SBT-based Scala project. …
- Add libraries. …
- Run Spark program.